matrix determinant
Matrix determinant
A determinant measures the volume of the image of a unit cube by the transformation; it is a function that outputs a single number. (When the number of dimensions of the domain and image differ, this volume is zero, so that such "determinants" are never considered.)
For instance, a rotation preserves the volumes, so that the determinant of a rotation matrix is always 1. When a determinant is zero, the linear transform is "singular", which means that it loses some dimensions (the transformed volume is flat), and cannot be inverted.
It is to note that historically, the formula for determinant was originally discovered when solving systems of linear equations, while the axioms were later identified and used to show that the formula was the unique function satisfying these natural conditions.
Definition
The determinant, \[\det:\mathbb{R}^{n\times n}\to\mathbb{R}\], is a unique function that satisfies the following properties:
- The determinant of the identity matrix is 1
- The exchange of two rows multiplies the determinant by -1
- Multiplying a row by a scalar multiples the determinant by that scalar
- Adding a multiple of one row to another row does not change the determinant
In other words, to every square matrix \[A\] we assign a number \[\det(A)\] in a way that satisfies the above properties, i.e. these general properties are enough to specify uniquely what number you should get when you put in a given matrix.
Axioms
Some sources may also define the determinant function with axioms.
Axiom 1 (Homogeneity in each row): If matrix \[B\] is obtained from matrix \[A\] by multiplying one row, say, the \[i\]th row of \[A\] by a scalar \[\alpha\], then \[\det(B)=\alpha\det(A)\], i.e. \[\det(A_{1},\dots,\alpha A_{i},\dots, A_{n})=\alpha\det(A_{1},\dots,A_{i},\dots,A_{n})\].
Axiom 2 (Invariance under row addition): If matrix \[B\] is obtained from matrix \[A\] by adding one row, say the \[k\]th row of \[A\] to the \[i\]th row then \[\det(B)=\det(A)\], i.e. \[\det(A_{1},\dots,A_{i}+A_{k},\dots,A_{k},\dots,A_{n})=\det(A_{1},\dots,A_{i},\dots,A_{k},\dots,A_{n})\].
Axiom 3 (The determinant of the identity matrix is one): \[\det(I_{n\times n})=1\].
Theorem
Based on the axioms defined, we can deduce several more properties of the determinant function as a consequence of Axiom 1 and 2.
Theorem 1:
If some row of matrix \[A\] is the zero vector, then \[\det(A)=0\].
Assume the \[i\]th row, \[A_{i}\], of \[A\] is the zero vector. Then,
Which implies that \[\det(A)\] can only be 0 for that equality to hold true.
Theorem 2:
If matrix \[B\] is obtained from matrix \[A\] by adding a scalar multiple of one row, say, the \[k\]th row of \[A\] multiplied by a scalar \[\alpha\] to the \[i\]th row, then \[\det(B)=\det(A)\], i.e. \[\det(A_{1},\dots,A_{i}+\alpha A_{k},\dots,A_{k},\dots, A_{n})=\det(A_{1},\dots,A_{i},\dots,A_{k},\dots,A_{n})\].
It is trivial if \[a=0\]. Assume that \[a\ne 0\]. Then,
Theorem 3:
If matrix \[B\] is obtained from matrix \[A\] by interchanging two rows of \[A\] , then \[\det(B)=(-1)\det(A)\], i.e. \[\det(A_{1},\dots,A_{i},\dots,A_{k},\dots,A_{n})=(-1)\det(A_{1},\dots,A_{i},\dots,A_{k},\dots,A_{n})\].
Theorem 4:
If two rows of matrix \[A\] are equal, then \[\det(A)=0\].
As a consequence of Theorem 3, if we switch the two equal rows of \[A\] to form an (identical) matrix \[B\], then \[\det(A)=(-1)\det(B)\], implying \[\det(A)=\det(B)=0\].
Intuition
Here.
\[2\times 2\]
Consider a matrix \[A\],
we know that for \[A\] to have an inverse, \[\frac{1}{ad-bc}\] must be solvable, therefore \[ad-bc\] must not equal to zero. In mathematical form, \[ad-bc=\det(A),\,\det(A)\ne0\].
Intuition
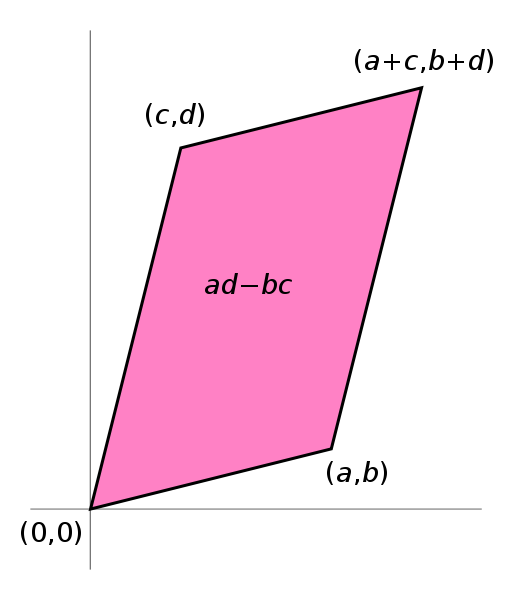
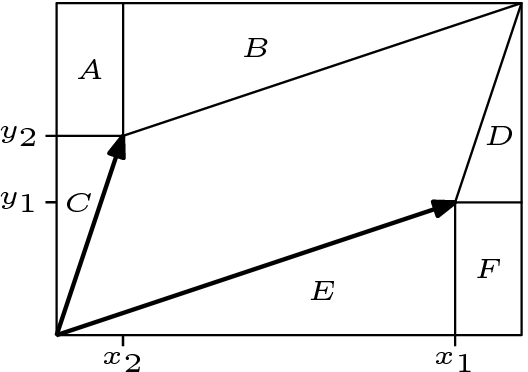
The formula for the area of the parallelogram, \[ad-bc\] can be derived via:
The fact that the area of the parallelogram created by the column vectors of a \[2\times 2\] matrix coincides with the value of the determinant of that matrix is no coincidence.
In fact, our definition (or axioms) for determinants make quite reasonable postulates for a function that measures the area of the region enclosed by the vectors in the matrix.
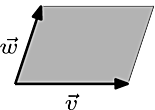

For Axiom 1, i.e. multiplying a row by a scalar will result in it's determinant being multiplied by that scalar, we can understand it by taking the area enclosed by two vectors defined as \[\vec{v}\] and \[\vec{w}\], defined as \[\begin{pmatrix} v_{1}&w_{1}\\v_{2}&w_{2} \end{pmatrix}\], then scaling one of the vector by a scalar, where \[k=1.4\], will scale the area by that scalar as shown in the diagram.
Although we defined that multiplying a row by a scalar multiples the determinant by that scalar, here we are multiplying a column not a row. However, because the transpose of a matrix will still have the same determinant, i.e. \[\det(A)=\det(A^{T})\], this distinction does not really matter in this context.
We can illustrate Theorem 2, i.e. determinants being unaffected by pivoting, in a similar manner.
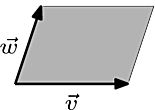
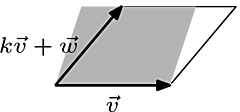
Although the region formed by \[\vec{v}\] and \[k\vec{v}+\vec{w}\], where \[k=0.35\], is slightly slanted than the original region, the two have the same base and height, hence the same area.
For Theorem 3, we define \[\vec{v}=\begin{pmatrix} 1\\3 \end{pmatrix}\] and \[\vec{u}=\begin{pmatrix} 4\\2 \end{pmatrix}\].


Then, \[\det\begin{pmatrix} 4&1\\2&3 \end{pmatrix}=10\] and \[\det\begin{pmatrix} 1&4\\3&2 \end{pmatrix}=-10\], which tells us that the sign returned by the determinant reflects the "orientation" or "sense" of the box.
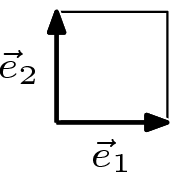
Finally, a square defined by an identity matrix, or sides of 1, will have an size of 1, which is just a restatement that \[\det(I_{n\times n})=1\].
\[3\times 3\]
See Laplace expansion and rule of Sarrus.
Determinants and volumes
See for one of the proofs for the equivalence of the determinant and volume function of parallelepipeds.